
As someone who is always finding inspiration for current or future role-playing campaigns, I tend to amass a lot of pictures I think would serve well as character inspiration. I also collect pictures of everyday people—whether realistic, fantastical, or cyberpunk-inspired—because when it comes to presenting a rich and lived-in world, I want all of my NPC tokens to look distinct and have a bit of character all their own.
No matter how organized I try to be however, over time this results in my having a number of duplicates, images I’ve either been inspired by at different times or that were collected in great sweeps of various online albums. These files invariably have different names on the harddrive, and the directories are large enough that manually hunting for duplicates is a fool’s errand. Luckily, computers are quite good at this kind of repetitive, analytical task, and during a round of spring cleaning this weekend, I put programmatic powers to use to save me a lot of headache.
While there are a number of de-duplication solutions out there, I wanted something that could make use of the new Linux machine I put together last month, where I could automate as much of the process as possible, since I had a number of directories and file types to sort through. Enter fdupes, a small command-line file processor that searches not only filenames and sizes (as some “dedupe” software solutions do), but actually reads the data stored on the disk to see if files contain the same content.
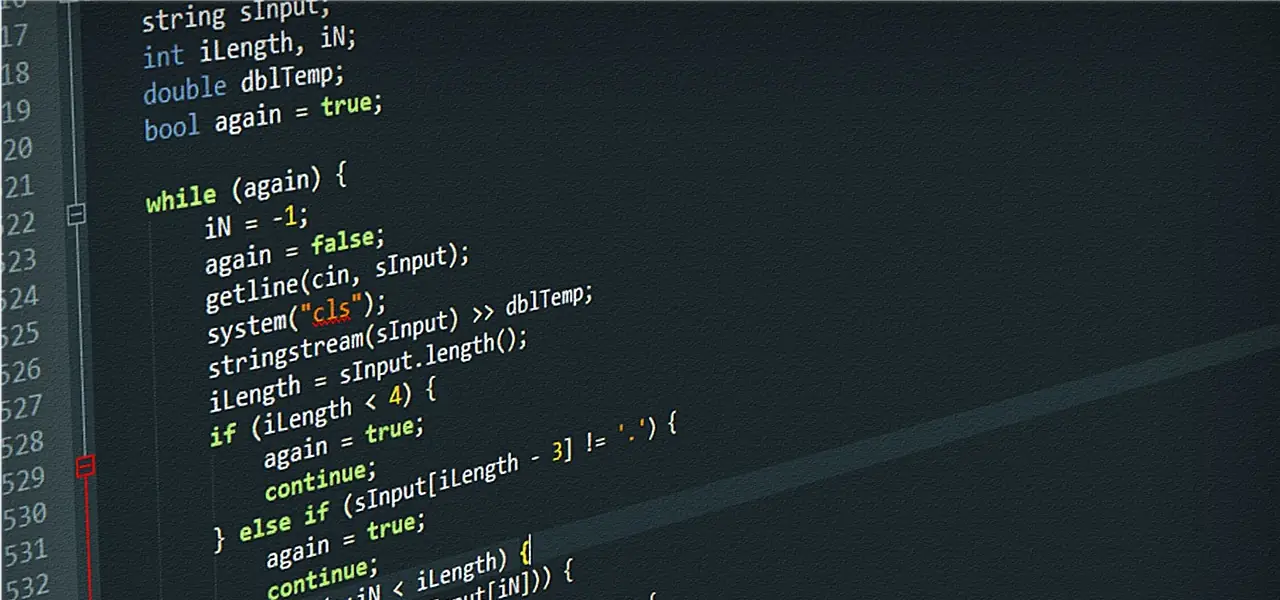
Running fdupes with the following options, I quickly had a list of every duplicated file, and could decide which copy I wanted to keep, to help me pre-prune my filesystem and reduce the amount of moving around I’d have to do later:
poetics@tengu:~$ fdupes -rnASd Game\ Pictures/
-r --recurse for every directory given follow subdirectories encountered within
-n --noempty exclude zero-length files from consideration
-A --nohidden exclude hidden files from consideration
-S --size show size of duplicate files
-d --delete prompt user for files to preserve and delete all othersAll in all I had 351 duplicate files in my picture directory, which is far better than I feared, and which would have been an impossible task to effectively hunt through manually. I got to re-sorting my pictures into appropriate categories for future use.
But wait, there’s more!
Good filesystem hygiene isn’t simply about removing duplicates and enforcing proper directory structure, however. It’s also about appropriate use of size and advances in formatting to make sure relevant files can be as effectively used and sent when necessary. Enter Google’s “webp” format, a new-ish graphic format that has better compression and better quality than the aging GIF, JPEG, or PNG standards.
Now, I am very much not a fan of Google as an institution, or the many business decisions they’ve made which I feel have eroded user privacy in the pursuit of the all-mighty profit margin, but I will absolutely give their engineers credit that they have come up with some amazing technologies, and often those advances are presented for free and with available source code. As a huge proponent of open-source software, my hat’s off to those individuals for that.
In this case, we turn to a small suite of tools Google has released for converting files into the webp format, including binaries which run perfectly smoothly on my Linux command-line. While these tools can handle things like animated images and advanced transparency layers, my needs were much simpler, and so my use case as well.
In short I wanted to find all files of type “.jpg” and convert them to “.webp”, keeping the quality ratio at around 90%. This would leave me with files that were roughly half the size of the original, with no perceptible loss of quality or fidelity. I would then do the same with any “.jpeg” and any “.png” files. Yes, I could have thrown together a single command to handle all of these cases, but I wanted to take it one step at a time to make sure my process was sound before going hog-wild.
poetics@tengu:~$ find . -name "*.jpg" -exec cwebp -q 90 '{}' -o '{}'.webp \;
poetics@tengu:~$ find . -name "*.jpeg" -exec cwebp -q 90 '{}' -o '{}'.webp \;
poetics@tengu:~$ find . -name "*.png" -exec cwebp -q 90 '{}' -o '{}'.webp \;After verifying that the files did indeed meet my quality needs, I removed the originals with a quick stroke of the keyboard. However, I was still left with a large number of files that all had their old extension as part of the filename, such as “human_03.jpg.webp” and that certainly wouldn’t do.
Using bash’s simple looping capabilities, I wrote a script that would find all instances of “.jpg.webp” and strip out the offending text, repeating the same with “.jpeg.webp” and “.png.webp”—there are many ways I could have done this, but that’s the beauty and power of working with the Linux command line.
poetics@tengu:~$ for file in *.jpg.webp;
> do mv "$file" "${file%.jpg.webp}.webp";
> doneIn the end, I was left with a deduplicated file hierarchy that took up less space on disk, with files that were all converted to the same format in case I needed to edit, share, or copy them elsewhere (such as within my virtual table top software).
Housecleaning!
Header image by Christopher Kuszajewski from Pixabay, a fantastic source for royalty-free stock images












{kind=link}